自分が運営している複数の個人プロダクトを横断的に分析するために、Claude Codeを分析エンジンとして活用する analysis リポジトリを構築しました。最初のターゲットは honn.me のファネル分析。GitHub Actionsでデータ収集を自動化し、Claude Codeで分析するハイブリッド方式に至るまでのストーリーを、失敗談も含めて書いていきます。
honn.meは本の推薦文を共有するサービスで、ユーザーの行動をDBのイベントログとして記録しています。ファネル分析だけならGA4でもできるんですが、やりたかったのはもっと広い話で、DBのイベントログやアプリケーション固有のメトリクスなど、あらゆるデータソースから自由に数字を引っ張ってきて分析すること。GAはあくまでページビュー周りのツールなので、アプリケーション内部のイベントやビジネスロジックに紐づくデータまではカバーしきれない。
たとえばhonn.meのDBには page_view_home → title_input_focus → book_select → create_button_click → share_button_click というイベントが記録されています。これをファネルとして見るだけでなく、「特定のメタデータを持つイベントだけ抽出したい」「DB上のユーザー属性と掛け合わせたい」といった柔軟な分析がしたい。そしてそれを自然言語で指示できたら最高だなと。
もう一つの動機として、分析基盤を作ること自体が、プロダクトの解像度を上げるという期待もありました。「何を計測すべきか」を考える過程で、プロダクトの課題が見えてくるのではないかと。
いくつかの設計方針を決めて始めました。
config/projects.json でプロジェクト情報を管理し、自分が運営するすべてのプロダクトを一元的に分析できるようにする。honn.meは最初のターゲットだが、他のプロダクトもスクリプトとconfig追加だけで対応できる設計projects.json には env_key パターンだけを記述するoutput/{project}/{date}/data/ に日次でデータを出力。時系列で比較できるようにする1// config/projects.json のイメージ 2{ 3 "projects": [ 4 { 5 "name": "honn.me", 6 "env_key": "HONN_ME", 7 "database_url_env": "HONN_ME_DATABASE_URL" 8 } 9 ] 10}
最初にClaude Codeにリポジトリの雛形を作ってもらいました。ディレクトリ構成、TypeScriptの設定、共通ユーティリティ。ここは本当にスムーズで、指示を出してから数分で動く状態になりました。
当初はいくつかのテーブルからデータを引っ張る想定でしたが、途中でEventテーブルに集約する方針に転換しました。honn.meのイベントログは events テーブルに event_type と metadata で記録されているので、ここだけ見ればファネル分析に必要なデータはすべて揃う。
1// scripts/honn.me/fetch-db-metrics.ts のイメージ 2const funnelEvents = [ 3 'page_view_home', 4 'title_input_focus', 5 'book_select', 6 'create_button_click', 7 'share_button_click', 8] as const 9 10const results = await pool.query(` 11 SELECT event_type, COUNT(*) as count 12 FROM events 13 WHERE event_type = ANY($1) 14 AND created_at >= $2 15 AND created_at < $3 16 GROUP BY event_type 17`, [funnelEvents, startDate, endDate])
Render.comのPostgreSQLに接続する際、SSL設定でハマりました。sslmode=require だけでは足りず、接続文字列の調整が必要でした。さらにスキーマ名の指定も最初は間違えていて、Claude Codeに修正してもらいながら進めました。
毎日の分析結果をSlackに通知する仕組みを作りました。Block Kitを使ってファネルを可視化しています。
1// scripts/_shared/notify-slack.ts で構築するBlock Kit 2const blocks = [ 3 { 4 type: 'header', 5 text: { type: 'plain_text', text: '📊 honn.me Daily Funnel Report' } 6 }, 7 { 8 type: 'section', 9 text: { 10 type: 'mrkdwn', 11 text: funnelSteps.map(step => 12 `${step.emoji} ${step.label}: *${step.count}* (${step.rate}%)` 13 ).join('\n') 14 } 15 } 16]
実際にSlackに届くレポートはこんな感じです。
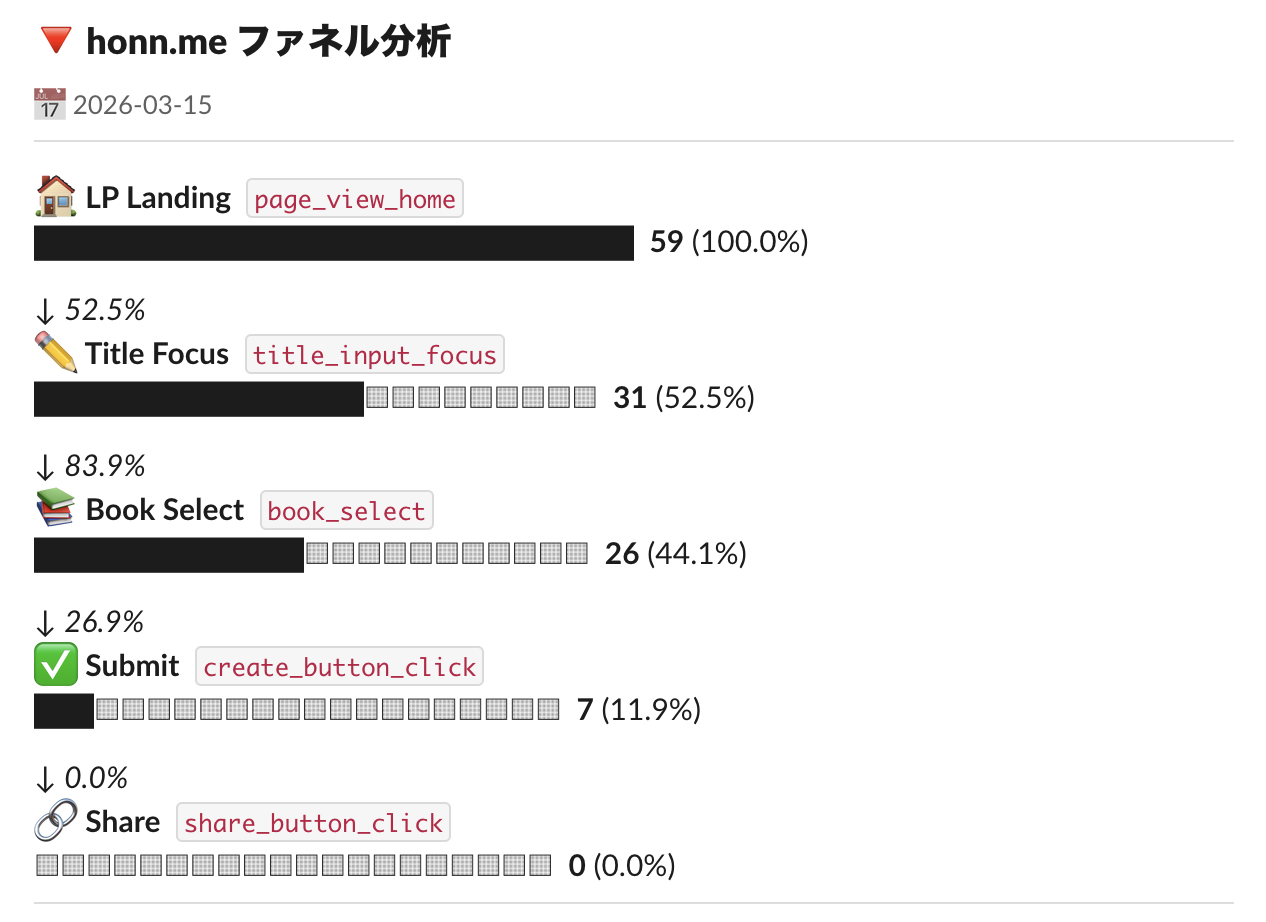
各ステップの転換率が一目でわかるので、日々の変化を追いやすくなりました。
最終的にデータ収集をGitHub Actionsで自動化しました。ここで重要なのは、GitHub Actionsの役割はあくまで「日次の定点記録」だということ。毎日同じクエリを叩いて、その日のファネル数値をJSONに保存し、Slackに通知する。判断や解釈は一切しない、淡々とした記録係です。
1# .github/workflows/fetch-metrics.yml 2name: Fetch Metrics 3on: 4 schedule: 5 - cron: '0 0 * * *' # 毎日UTC 0:00 6 workflow_dispatch: 7 8jobs: 9 fetch: 10 runs-on: ubuntu-latest 11 steps: 12 - uses: actions/checkout@v4 13 - uses: oven-sh/setup-bun@v2 14 - run: bun install 15 - run: bun run scripts/honn.me/fetch-db-metrics.ts 16 env: 17 HONN_ME_DATABASE_URL: ${{ secrets.HONN_ME_DATABASE_URL }} 18 - run: bun run scripts/_shared/notify-slack.ts 19 env: 20 SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL }}
Claude CodeにはCoworkというVM上で長時間タスクを実行するモードがあります。「データ収集から分析まで全部Coworkに任せれば完全自動化できるのでは?」と考えて試してみました。
結果は全滅でした。
CoworkのVM環境にはネットワーク制約があり、外部のデータベースへの接続ができません。Render.comのPostgreSQLへの接続もタイムアウト。GitHub APIもSlack Webhookも叩けない。つまり、外部サービスとの通信が必要な処理はCoworkでは実行できないということがわかりました。
これがハイブリッド方式に至った直接的な理由です。GitHub Actionsは毎日決まったクエリを叩いてデータをJSONに記録する「定点観測係」。Claude Codeはその蓄積されたデータを読み込んで、傾向の分析や仮説の提示を行う「分析係」。データ収集と分析の責務がきれいに分かれて、結果的には良い設計になりました。
ファネルを定義する過程で「このステップの間に何が起きているのか」を深く考えることになりました。分析基盤を作ること自体が、プロダクトの解像度を上げる行為だったと感じています。
実際のデータを見ると、title_input_focus → book_select の転換率が低いことがわかりました。ユーザーはタイトルを入力するところまでは来るが、本の選択で離脱している。これは本の検索UIに改善の余地があることを示唆しています。
Slackの通知でBlock Kitを使ったファネル可視化は見た目以上に便利でした。毎朝Slackを開くだけで、前日のファネル状況がぱっと見れる。ダッシュボードを別途開く必要がないのは、個人開発のスケール感にちょうど良い。
データを見ていて book_remove というイベントが気になりました。本を一度選択した後に削除するユーザーがいる。これは「間違えて選んだ」のか「比較検討している」のか。こういった解釈の余地がある指標を自然言語でClaude Codeに投げて議論できるのは、この分析基盤ならではの体験でした。SQLを書かなくても「book_removeが多い日の傾向を教えて」と聞けば分析してくれる。
最終的に落ち着いた構成は以下の通りです。
output/{project}/{date}/data/ に保存ポイントは、GitHub Actionsは「何が起きたか」を淡々と記録し、Claude Codeは「それが何を意味するか」を考える、という責務の分離です。定点記録は毎日安定して自動実行され、分析は必要なタイミングでClaude Codeと対話しながら行う。
pg ライブラリで接続config/projects.json)複数の個人プロダクトを横断的に分析するための analysis リポジトリを作りました。Coworkでの失敗を経て、GitHub Actionsでデータ収集、Claude Codeで分析というハイブリッド方式に落ち着きました。
個人開発の規模感では、専用のBIツールを導入するほどでもないけれど、GAだけではデータソースが限られる。DBのイベントログやアプリ固有のメトリクスまで含めて、自然言語で柔軟に分析できるこの構成は、ちょうど良い中間地点だと感じています。honn.meで仕組みが回り始めたので、次は他のプロダクトにも同じ基盤を横展開していく予定です。
分析基盤を作る過程でファネルの転換率からUXの課題が見えたり、「作ること自体がプロダクト改善」という体験ができたのは、やってみて良かったポイントです。
 blog.unresolved.xyz
blog.unresolved.xyz